The workbench, live
A reviewer can see the case and the policy at the same time.
The prior-auth workbench runs in your browser. Evidence boxes are drawn directly on the scanned, handwritten intake form, and every policy criterion links to the packet location that satisfies it.
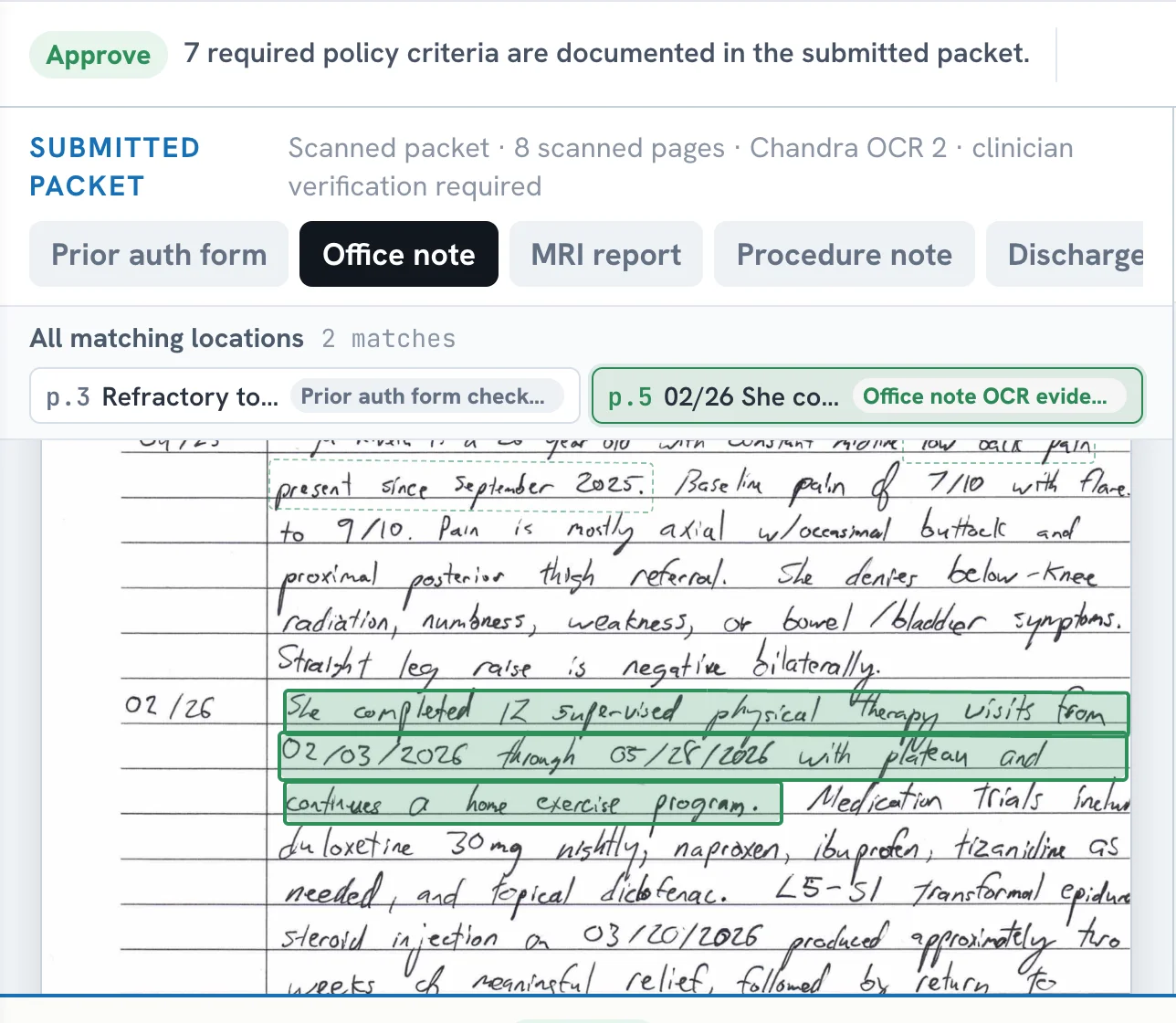
- Evidence spans anchored to the scanned page, down to a handwritten note that 12 physical-therapy visits plateaued
- Every criterion shows its packet locations and the verbatim policy excerpt that requires it
- OCR findings carry QA state, so a reviewer can agree, flag, or reject each match
- The disposition ships with a source-linked receipt, not just an answer
Open the workbench synthetic patient · real published policies